

现代CPU 的流水线设计
为什么需要流水线设计
CPU 指令的执行,概括性来讲是由:“取指(Fetch)-> 指令译码(Decode)-> 执行指令(Execute)”三个步骤组成的。出于对性能的考虑,自然希望这样一整条指令的执行是在一个时钟周期内完成的。采用这种思想设计的CPU 叫做单指令周期处理器(Single Cycle Processor)。
一个时钟周期的长短是固定的,然而不同指令的复杂程度不一样,比如对于CPU来说加减法运算比起位运算就复杂一点。所以,其实不同的指令执行的时间是不一样的。但是我们需要让所有指令都在一个时钟周期内完成,那就只好把时钟周期跟执行时间最长的那个指令设置成一样的。这就好比下课铃响了,但是老师还在讲课,虽然到了下课时间,但是因为老师还有其他的内容没有讲完,所以同学们都需要等待老师讲完在下课。
这样设计的后果就造成了,有一些简单的指令执行结束后,仍然需要等满一个时钟周期,CPU 就得等待,CPU 的性能就不能很好的发挥。
简单的指令执行完成后,需要等待满一个时钟周期,浪费性能
我们知道摩尔定律,CPU 的性能几乎已经压榨到了极限,对于如此近乎奢侈的浪费举动,现代CPU 的设计者自然会想各种办法去解决,这就得引入流水线的设计思想。
现代处理器的流水线设计
CPU 的执行过程,其实是由不同的电路模块组成的。取值阶段,需要一个译码器把数据从内存中取出来,写入到寄存器中;指令译码阶段,需要一个译码器,把指令解析成对应的控制信号、内存地址和数据;执行指令的时候,我们需要具体完成计算工作的ALU 。他们都是在独立的完成任务,把他们的工作串联起来,就是CPU 指令的执行过程。
很明显,我们不需要把时钟周期设置成整条指令执行的时间,只需要设置为一个独立的小步骤需要的时间。这样,每个小步骤的执行就不需要等待整条指令执行完毕才执行,可以直接执行下一条指令的对应的小步骤。
流水线执行示意图
从图示中可以看到,我们不需要再把时钟周期设置为和指令周期一样,而是将时钟周期设置为和指令周期中耗时最长的一个阶段时间一样即可。图中每一行表示正在执行的一条指令,以取指令为例,第一条指令的取指完成后,可以立即开始下一条指令的取指阶段,这大大减少了CPU 的等待时间。这样的协作模式,称为指令流水线。其中,每条指令的每一个独立的步骤,我们就称之为流水线阶段或者流水线级(Pipeline Stage)。
“取指(Fetch)-> 指令译码(Decode)-> 执行指令(Execute)”,这是一个三级的流水线。如果继续拆分“取指(Fetch)-> 指令译码(Decode)-> ALU计算(指令执行)-> 内存访问 -> 数据写回”,那它就是一个五级的流水线。
虽然我们不能通过流水线,来减少单条指令执行的“延时”这个性能指标。但是,通过流水线技术,提升了CPU 的“吞吐率”。从外部来看,CPU 好像是同时执行5条不同指令的不同阶段。就好像商品的生产线一样,不同分工的组件不断处理上游传递下来的内容,而不需要等待单件商品制作完成后,才启动下一件商品的生产过程。
流水线越长越好吗
上面提到的流水线技术,乍一看很好,它把一条指令拆分为不同的步骤,每个步骤又足够简单,所以执行一个小步骤的时钟周期可以设置的小一点,这变相的提升了CPU 的主频。那么,流水线是不是设计的越长越好呢?
答案是否定的,增加流水线深度,在同主频下,其实是降低了CPU 的性能。因为一个流水线的阶段,就需要一个时钟周期。如果我们把流水线拆分为30个阶段,那就需要30个时钟周期;而如果把任务拆分成10个阶段,就只需要10个时钟周期就能完成任务。这种情况下,30个阶段的3GHz主频的CPU ,其实和10个阶段的1GHz主频的CPU 的性能是差不多的。更糟糕的是,考虑到每个阶段都需要有对应的流水线寄存器的开销,30个阶段流水线性能可能还要更差一点。
提升流水线的深度,必须要和提升CPU 主频同时进行。因为在单个流水线阶段(Pipeline Stage)能够执行的功能变简单了,也就意味着单个时钟周期内能够完成的事情变少了。所以,只有提升时钟周期,CPU 在指令的响应时间这个指标上才能保持和原来相同的性能。显然,流水线深度增加,对应着我们需要的电路数量变多了,即需要使用的晶体管也就变多了。主频的提升和晶体管数量的增加都使得CPU 的功耗变大了,对应的耗电和散热也就更严重了。
看下面这个例子。
int a = 1 + 1; //整数加法指令,耗时 200ps
int b = 2 * 2; //整数乘法指令,耗时 300ps
float c = 3.14 * 2; //浮点数乘法指令,耗时600ps如果使用单指令周期的CPU 运行,时钟周期与耗时最长的指令的指令周期设置为相同的,那就是600ps。那执行三条指令就需要1800ps。
如果采用的是6级流水线CPU ,每一个流水线的阶段假设需要100ps。那么,在这三条指令执行过程中,当指令一的第一个100ps的阶段结束之后,第二条指令的第一个阶段就开始执行了;第二条指令的第一个阶段执行完毕后,第三条指令的第一个阶段就开始执行了。这种执行模式下,三条指令顺序执行所需要的时间为800ps。
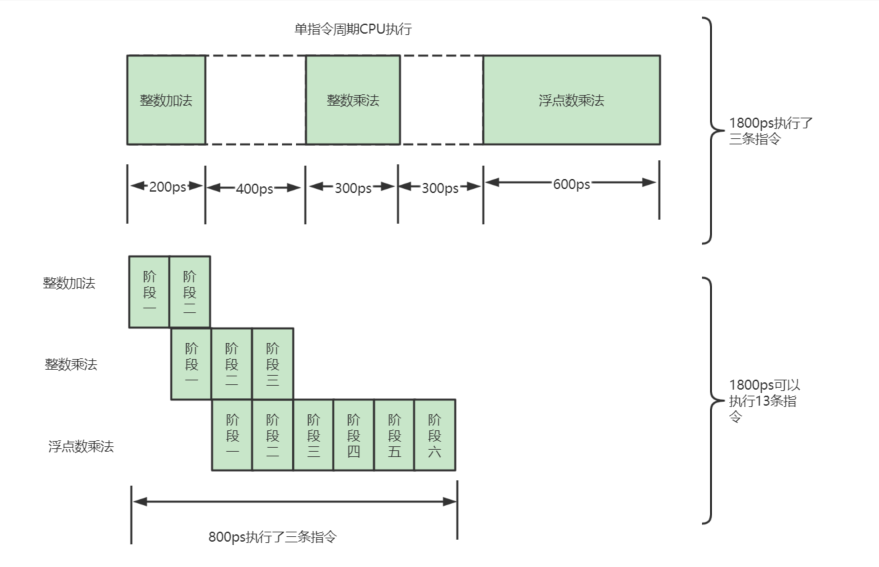 通过这幅图可以看出,使用流水线之后,吞吐率是未使用流水线的4.33倍,时钟频率是上面的6倍。虽然流水线技术并不能缩短单条指令的响应时间,但是可以在相同时间内运行更多地指令,提升吞吐率以提升
通过这幅图可以看出,使用流水线之后,吞吐率是未使用流水线的4.33倍,时钟频率是上面的6倍。虽然流水线技术并不能缩短单条指令的响应时间,但是可以在相同时间内运行更多地指令,提升吞吐率以提升CPU 的性能。
接着看下面的例子。
int a = 1 + 1; //整数加法指令,耗时 200ps
int b = a * 2; //整数乘法指令,耗时 300ps
float c = 3.14 * b; //浮点数乘法指令,耗时600ps会发现,指令2不能在指令1第一个阶段执行完后开始执行,因为指令2的执行是依赖指令1的计算结果的。同理,指令3会依赖指令2的计算结果。这种情况下,即使采取流水线技术,这三条指令执行完成的时间,也是200 + 300 + 600 = 1100ps ,而不是之前的800ps。这个依赖问题,就是计算机组成中所说的冒险(Hazard)问题。这个是数据层面的依赖,即数据冒险,实际应用中还会有结构冒险、控制冒险等其他依赖问题。
对应这些冒险问题,也有乱序执行、分支预测等相应的解决方案。(会有专门的博客去学习,记录)。
流水线越长,冒险的问题就越难解决,因为,同一时间同时运行的指令太多了。如果只有3级流水线,我们可以把后面没有依赖关系的指令放到前面来执行,这就是乱序执行的技术。但是,如果有20级的流水线,意味着我们要确保这20条指令之间没有依赖关系,这就有点难搞了,毕竟我们平时写的程序,前后代码通常是会有联系的,几十条没有依赖关系的指令可不好找。这也是超长流水线的执行效率反而降低的一个重要原因。
Comments